



DeepSeek开源周正式拉开帷幕,为AI社区带来了一系列开源代码库,北京时间周一上午九点,DeepSeek公布了开源周的第一个项目:FlashMLA;发布后,FlashMLA迅速成为全球开发者关注的焦点,在GitHub上的Star数已突破5000。
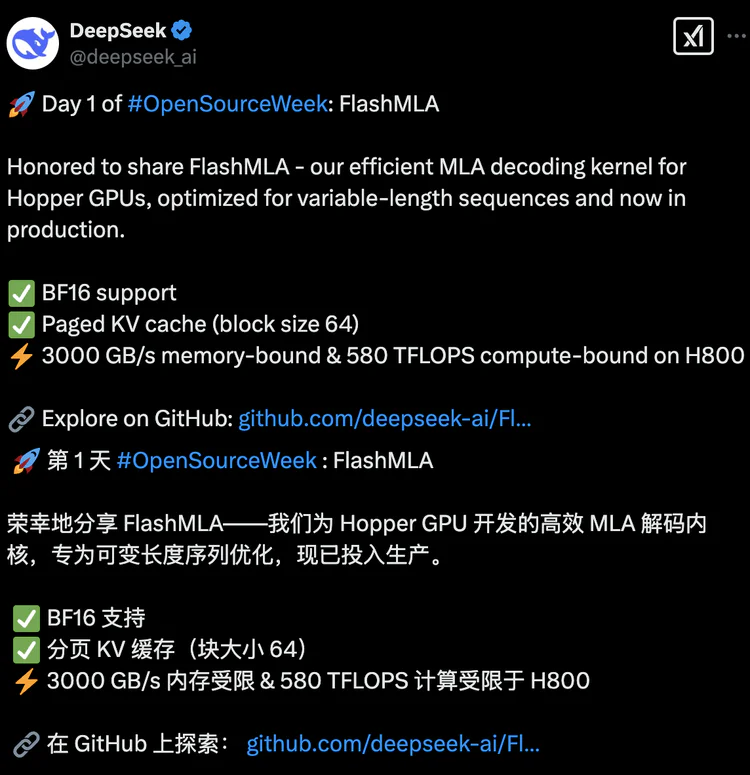
FlashMLA是DeepSeek专为英伟达HopperGPU设计的高效MLA(Multi-Head LatentAttention)解码内核,用于优化可变长度序列的推理服务,其目标是在H100等Hopper GPU上实现更快的推理速度,且所有代码均经过实际业务场景验证,目前正处于持续发布中。
一、FlashMLA的核心价值与技术亮点
1. 解决变长序列处理痛点
传统方法在处理不同长度的输入序列(如用户评论、对话文本)时,存在静态填充(Padding)导致的算力浪费或截断造成的信息丢失问题。FlashMLA通过**分页键值缓存(Paged KV Cache)**和动态内存分配机制,实现了显存资源的智能调度,类比“智能分拣系统”,显著提升GPU利用率1510。
2. 技术创新与性能突破
BF16混合精度支持:兼顾计算效率与精度,适应大模型的高性能需求。
分块调度与异步内存预取:块大小为64的分页KV缓存技术,结合类操作系统的虚拟内存管理,释放Hopper GPU的Tensor Core潜力。
极致性能指标:在H800 GPU上,显存带宽达3000 GB/s(内存受限场景),算力峰值达580 TFLOPS(计算受限场景),接近硬件理论极限。
二、实际应用与开源意义
1. 生产环境验证与成本优化
FlashMLA已在DeepSeek的生产环境中应用,通过动态资源分配减少GPU服务器需求,直接降低推理成本。例如,长上下文对话场景的推理速度提升显著,为大模型商业化落地提供支持。
2. 推动AI开源生态
开源首日,FlashMLA的GitHub仓库即获1700星,吸引全球开发者关注。马斯克旗下xAI的大模型Grok3评价其为“涡轮增压引擎”,认为其性能可媲美FlashAttention等顶尖方案410。DeepSeek此举也被视为对OpenAI封闭策略的挑战,网友称其“以开放共赢定义AI未来”。
三、安装要求与快速上手
• 运行环境:需Hopper架构GPU(如H800)、CUDA 12.3+、PyTorch 2.0+16。
• 安装与测试:通过python setup.py install安装,运行python tests/test_flash_mla.py进行基准测试24。
四、行业影响与后续展望
1. 开源周后续计划
DeepSeek将在2月24日至28日陆续开源4个代码库,内容可能涉及AI算法优化、模型轻量化等,甚至被猜测包含AGI相关技术。
2. 行业趋势推动
开源已成为AI领域的新趋势,国内头部厂商如阿里、百度也加速布局。例如,阿里通义千问系列衍生模型数已超Meta的Llama,成为全球最大开源模型系列。
FlashMLA的发布不仅是技术突破,更是DeepSeek推动开放生态的里程碑。其通过硬件级优化与开源共享,为AI开发者提供了高效工具,同时为行业树立了“透明化技术探索”的标杆。后续项目的开源值得期待,或将进一步重塑AI技术发展的格局。


